

범퍼카 토토 학습의 기본 개념
범퍼카 토토 학습에는 각 장치가 로컬 데이터를 사용하여 모델을 훈련하고 해당 업데이트만 중앙 서버로 보내는 작업이 포함됩니다 중앙 서버는 이러한 업데이트를 집계하고 글로벌 모델을 업데이트합니다이 프로세스는 데이터 분산화 및 개인정보 보호를 제공합니다
범퍼카 토토 학습은 데이터 개인 정보를 보호하고 통신 비용을 절감해야 하는 오늘날의 세계에서 매우 중요한 기술이 되었습니다
기존 기계 학습 및 범퍼카 토토 학습
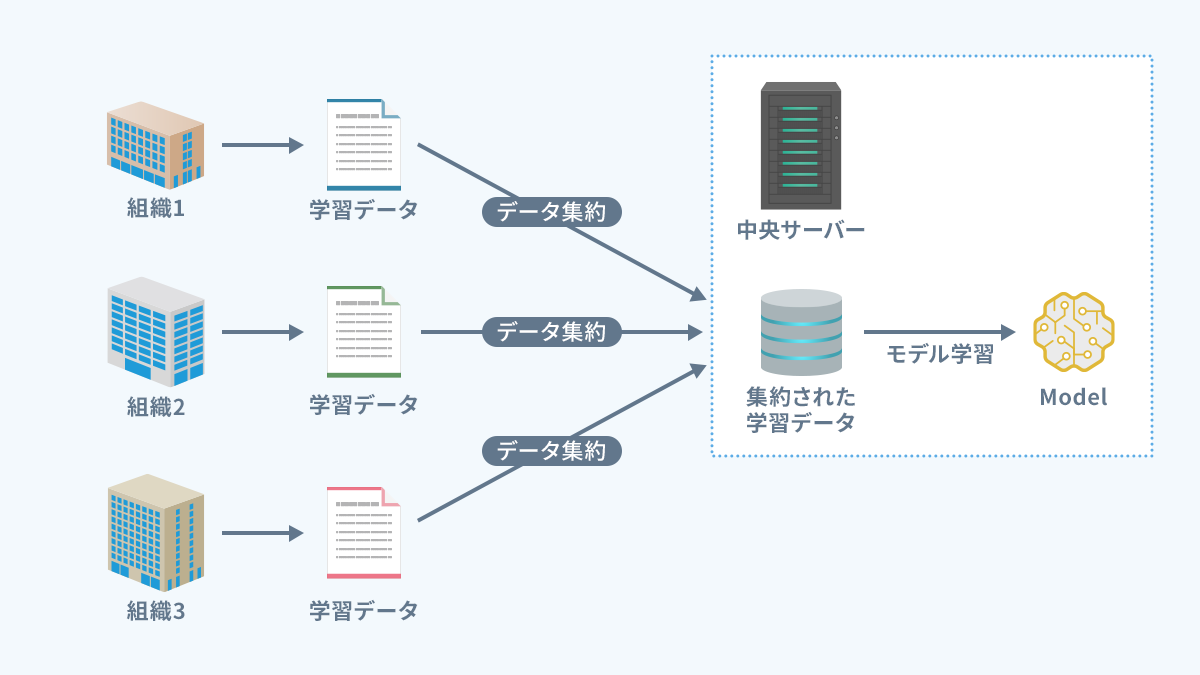
전통적인 기계 학습
- 데이터를 중앙 서버에 집계하고 모델 훈련
- 문제: 개인정보 보호 위험, 전송 비용, 서버 부하 집중
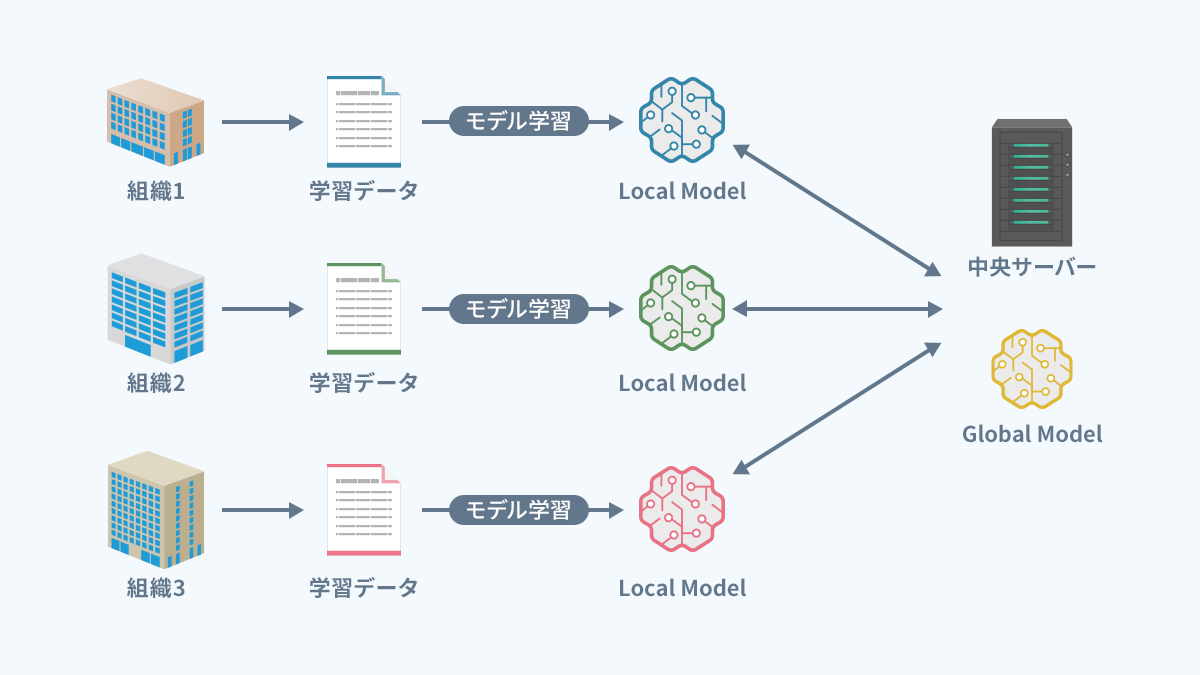
범퍼카 토토학습(분산학습형)
- 초기 모델 배포: 중앙 서버가 초기 기계 학습 모델을 각 클라이언트(기기 또는 조직)에 배포합니다
- 로컬 학습: 각 클라이언트는 자체 로컬 데이터를 사용하여 로컬에서 분산 모델을 학습합니다(데이터는 외부로 전송되지 않음)
- 모델 업데이트 보내기: 각 클라이언트는 로컬로 훈련된 모델 업데이트를 중앙 서버로 보냅니다
- 모델 통합: 중앙 서버는 각 클라이언트로부터 받은 업데이트를 통합하고 글로벌 모델을 업데이트합니다
- 업데이트된 글로벌 모델을 각 클라이언트에 다시 배포하고 위의 과정을 반복
범퍼카 토토 학습 프레임워크 “Flower” 소개
다음 기능을 갖춘 범퍼카 토토 학습용 오픈 소스 프레임워크:
- 유연한 클라이언트-서버 모델을 지원하며 다양한 기계 학습 라이브러리(PyTorch, TensorFlow 등)와 통합될 수 있습니다
- 대규모 범퍼카 토토 학습 시스템을 구축할 수 있습니다 고도로 사용자 정의 가능하고 확장 가능합니다
- 범퍼카 토토 학습의 다양한 사용 사례를 지원할 수 있습니다
범퍼카 토토 학습 과제 및 Ray 사용
범퍼카 토토 학습 챌린지
이번에는 운영 문제에 중점을 두었습니다다음과 같은 문제가 있다고 생각합니다
- 클라이언트 참여 및 탈퇴 관리 ←대규모 FL 시스템 구현 및 운영 시 관리가 복잡함
- 클라이언트별로 동일한 소스코드와 환경을 준비하고 학습을 진행하는 것이 필요합니다
⇒Ray를 사용하여 이를 더욱 효율적으로 만드는 방법에 대해 생각해 보겠습니다
*또한 다음은 연결된 학습의 과제로 일반적으로 인용됩니다
- 클라이언트 간에 데이터 분포가 크게 다른 경우
- 통신량 줄이기
- 개인정보 보호
Ray 클러스터의 범퍼카 토토 학습
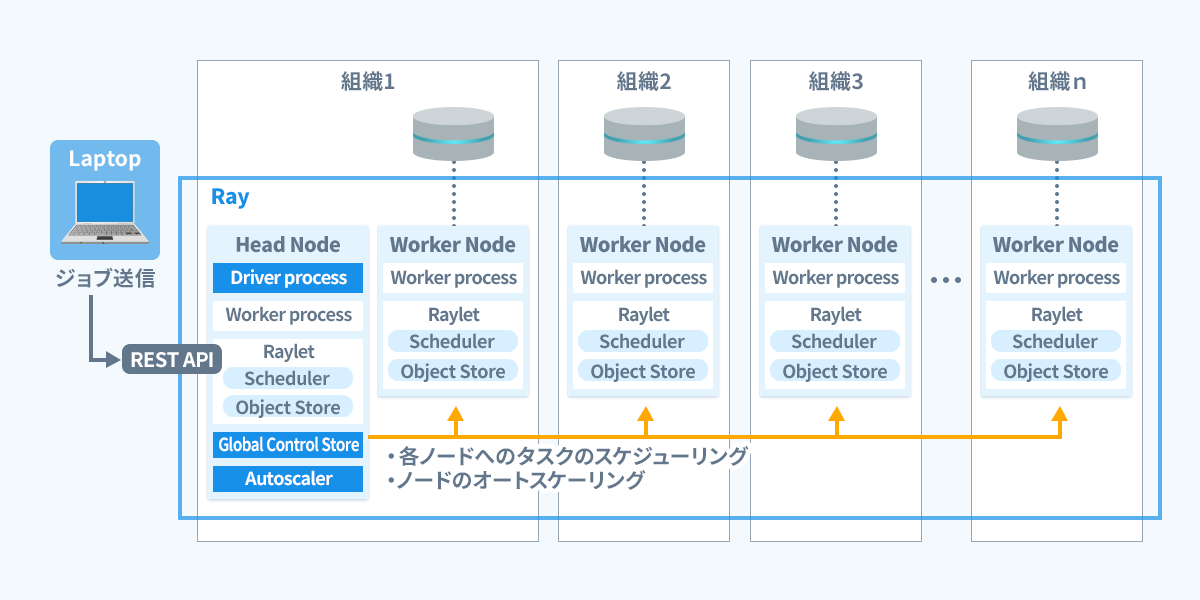
이제 Ray 클러스터에서 범퍼카 토토 학습을 구현하는 흐름을 간략하게 설명하겠습니다
- 레이 클러스터를 구축하세요
참조:https://docsrayio/en/latest/cluster/kubernetes/getting-started/raycluster-quick-starthtml
-
Ray의 작업 API를 사용하여 제휴 학습 작업을 제출하세요
-
Ray 헤드 노드는 각 컴퓨팅 노드에 대한 작업을 예약하므로 각 노드에서 처리를 실행할 필요가 없습니다필수 라이브러리도 설치됩니다
-
컴퓨팅 리소스는 필요에 따라 자동 확장됩니다(사용할 계산 노드를 지정하는 것도 가능합니다)또한 컴퓨팅 리소스의 합류 및 탈퇴를 관리할 수 있으며 대시보드에서 리소스 사용량, 실행 로그 및 각 프로세스의 상태를 확인할 수 있습니다
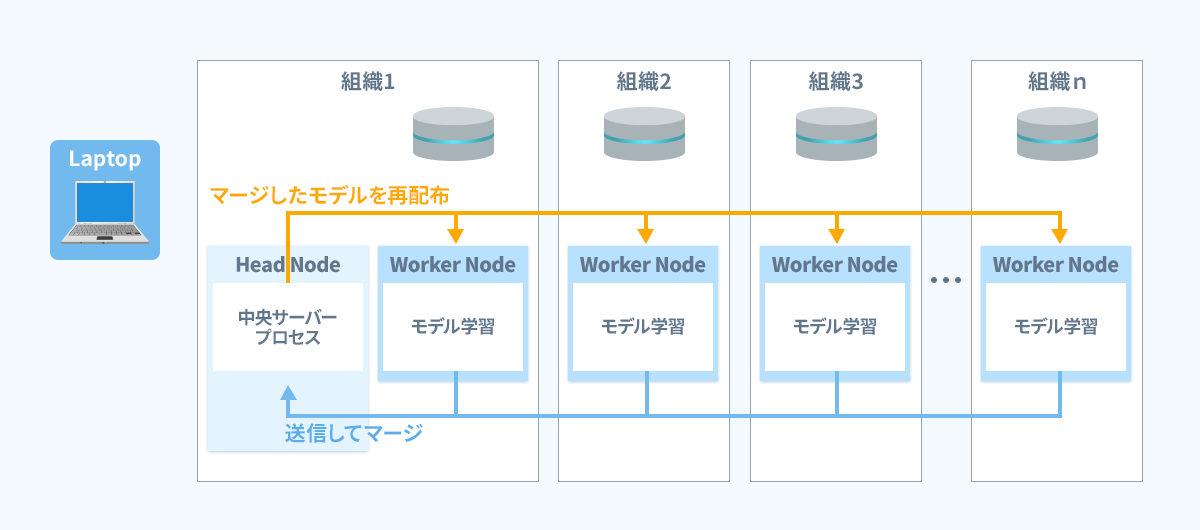
나머지 프로세스는 범퍼카 토토 학습의 흐름에 따라 실행됩니다
요약
👌 범퍼카 토토 학습은 데이터를 중앙 집중화하지 않고 분산된 장치에서 기계 학습 모델을 학습하는 방법입니다👌 통신 비용 절감과 데이터 보안을 강조하는 머신러닝 접근 방식입니다👌 Ray와 결합하면 동적 리소스 할당 및 클라이언트 관리가 더욱 효율적으로 이루어질 수 있습니다
일부 이미지는 인용문입니다
