

오늘은 SKYDIV 데스크톱 클라이언트 기능에 사용됩니다토토 결과을 잃지 않고 선 그래프를 단순화하는 방법
1 이를 실현하는 데 관련된 기능 및 과제 개요
SKYDIV의 성능 확인 기능 화면입니다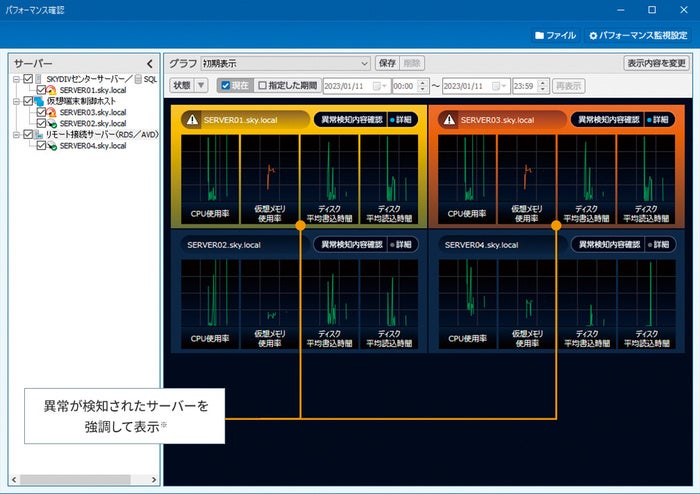
성능 확인 기능은 서버의 CPU 사용량과 메모리 사용량에 관한 것입니다시간별 선 토토 결과로 표현됩니다1주일 분량의 데이터는 수만 개의 플롯으로 구성되므로 데이터를 있는 그대로 처리하고 그리는 것은 엄청난 비용이 듭니다(또한 토토 결과를 많이 표시해야 합니다)
2 기계적으로 단순화하면 그래프의 토토 결과이 사라집니다
SKYDIV 데스크톱 클라이언트의 성능 확인 기능은 그렇게 큰 영역에 토토 결과를 그리지 않기 때문에 데이터를 솎아내는 작업이 필요하지만 아래의 샘플 데이터는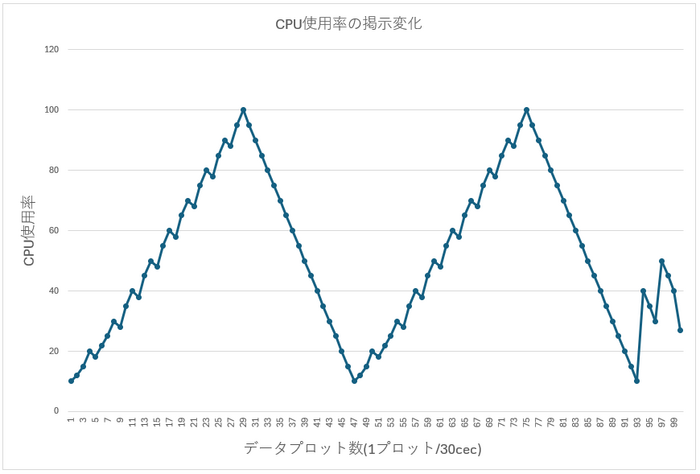
플롯을 기계적으로 1/10로 얇게 만듭니다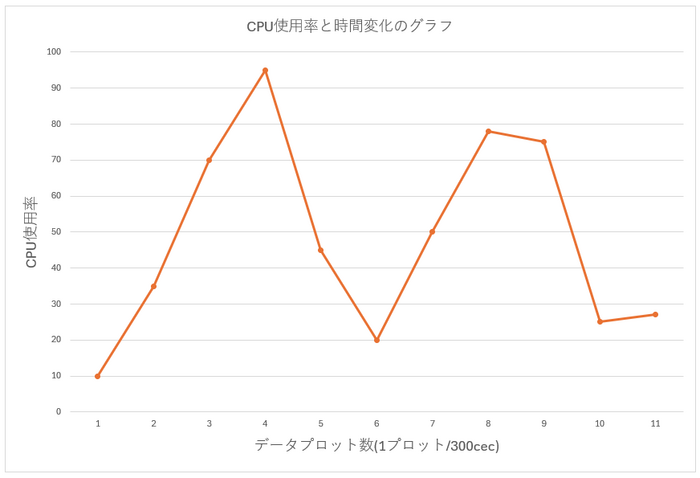
이렇게기계적으로 솎아내는 경우 피크 값이 채택되지 않을 수 있습니다(커뮤니티에서는 데이터를 솎아내는 것을 "다운샘플링"이라고도 표현합니다)
3. 기능 손실 없이 데이터 축소
따라서 SKYDIV에서는 선 토토 결과와 같은 시계열 데이터 플롯을 얇게 만드는 방법으로가장 큰 삼각형 세 개의 버킷을 채택했습니다
알고리즘에 대해 간단히 설명하겠습니다① 데이터 분할예를 들어, 10,000개의 플롯 데이터를 1500개로 줄이려면 이를 각각 20개의 데이터 세트로 나누십시오
②분할된 그룹 내에서 3개 포인트의 모든 조합을 생성위에 언급된 20개의 플롯 데이터 세트(P1 ~ P20)에서 각각 3개 조각을 결합합니다
S1:(P1,P2,P3)*순서는 중요하지 않으므로 20C3에는 총 1,140개의 플롯 세트가 있습니다 ⇒20!/{(20-3)! * 3!}=1140
③각각의 면적을 계산합니다아래 표시된 신발끈 공식을 사용하여 각 플롯 세트(삼각형)의 면적을 계산하십시오//C++에서 삼각형 면적 계산doublecalculateTriangleArea(const Point& p1, const Point& p2, const Point& p3)
4 플롯 세트에서 면적이 가장 큰 세 점을 선택
1번으로 나누어진 데이터에 대해 ②~4번을 반복하는데, 반복시 두 번째 이후 포인트 데이터 세트의 왼쪽 포인트가 이전 데이터 세트에서 결정된 오른쪽 포인트 좌표로 설정되어 3개의 좌표가 설정됩니다
4 실제로 데이터를 얇게 만들고 단순화합니다
이제 가장 큰 삼각형 3개 버킷 알고리즘을 사용하여 데이터를 얇게 만들고 단순화합시다!*샘플 프로그램은 CSV 파일에서 플롯을 읽고, 가장 큰 삼각형 세 개의 버킷을 사용하여 지정된 데이터 수까지 플롯 데이터를 얇게 만들고, 이를 CSV 파일에 저장하고, Excel에 토토 결과로 표시합니다
1주일 간의 CPU 사용량입니다45000개 플롯(X축은 약 600픽셀입니다)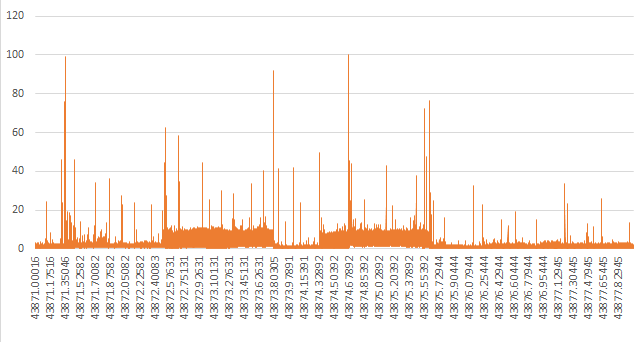
만약 당신이 진지하게 많은 플롯을 그리면, 그것은 채워넣는 것처럼 보일 것입니다2000개 플롯까지 원본 데이터의 1/20 이하로 플롯을 얇게 만듭니다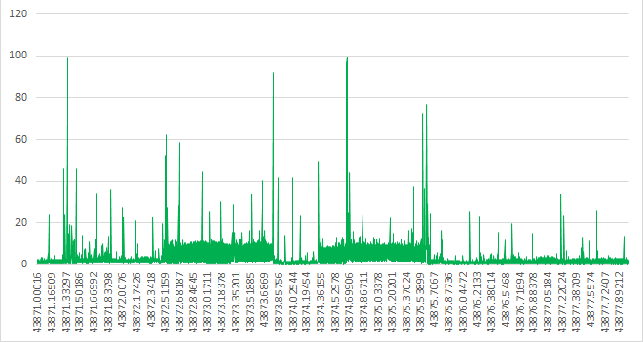
그렇게 큰 차이는 모르겠어요1000개 플롯, 원본 데이터의 1/45입니다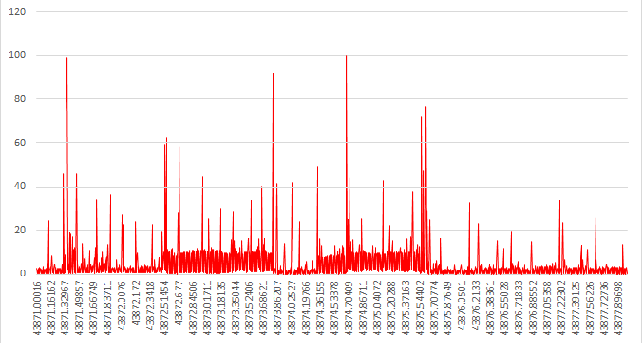
드디어 선이 보입니다500개 플롯, 원본 데이터의 1/90입니다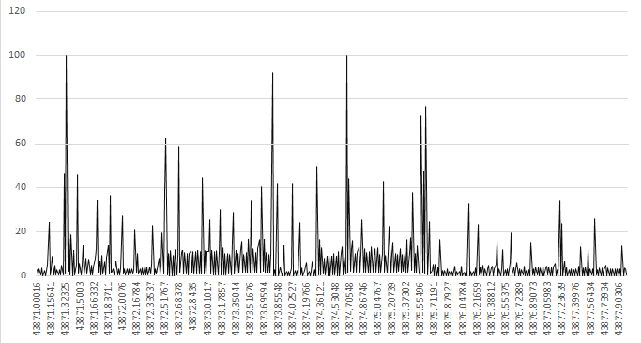
아주 괜찮아 보입니다 데이터를 얇게 만들고 더욱 단순화하겠습니다250개 플롯, 1/180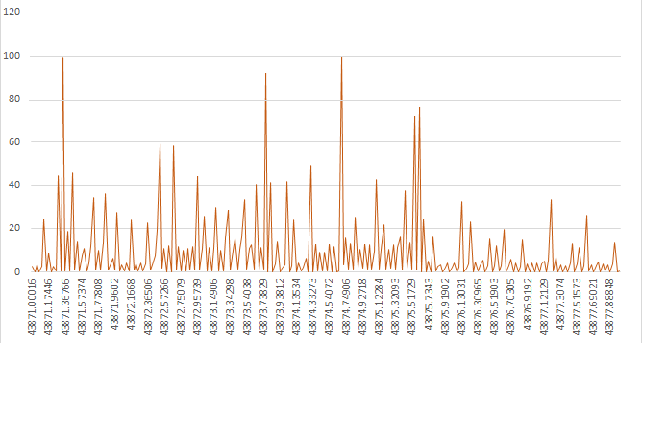
너무 거친가요?
5 마침내
이번에는 선 그래프의 토토 결과을 잃지 않고 단순화하는 방법을 설명하겠습니다가장 큰 삼각형 세 개의 버킷알고리즘을 사용하여 다운샘플링을 도입했습니다
좋은 점만 소개했지만, 물론 단점도 있습니다
- 단점 데이터가 적으면 그래프의 토토 결과이 없어집니다
만약 그리기 및 데이터 처리 비용이 걱정된다면 이것을 고려해 보십시오
그렇습니다
